Philippe Weinzaepfel
I am currently a Principal Research Scientist at Naver Labs Europe in the Computer Vision group.
My research interests include (but are not limited to):
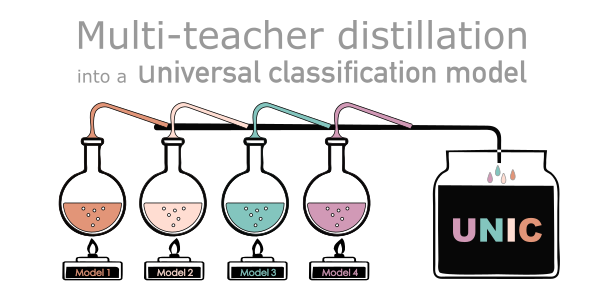
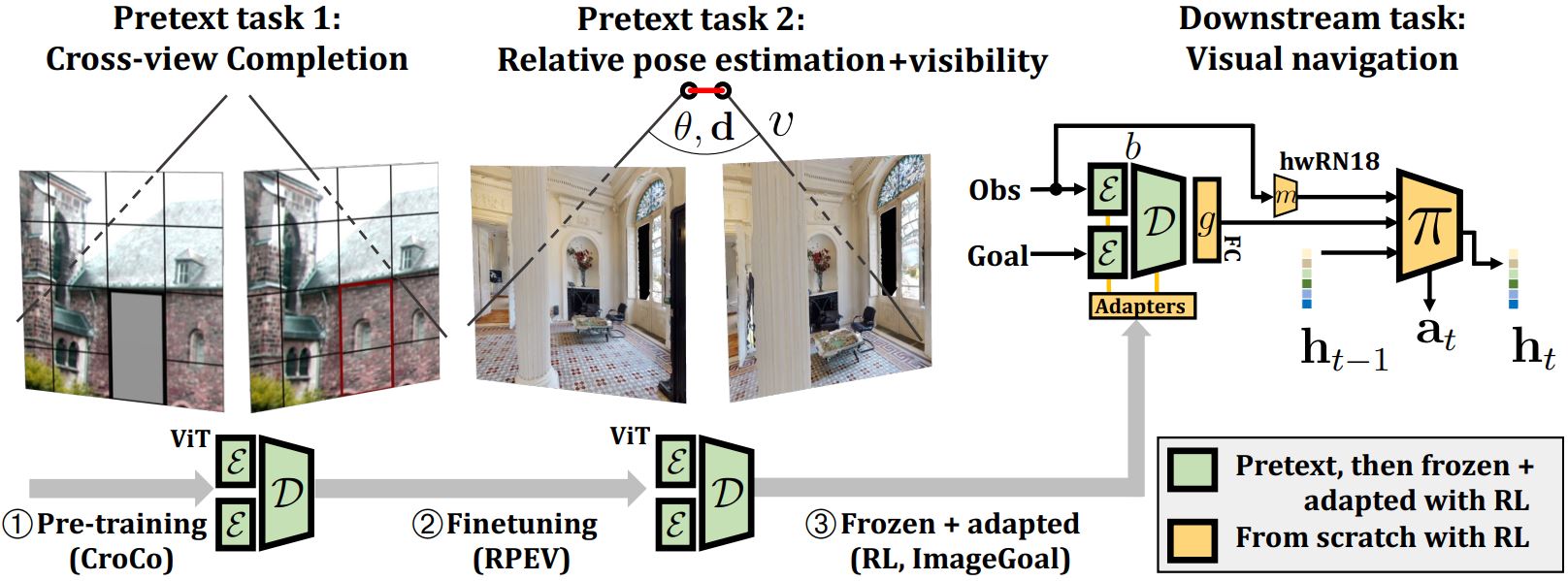
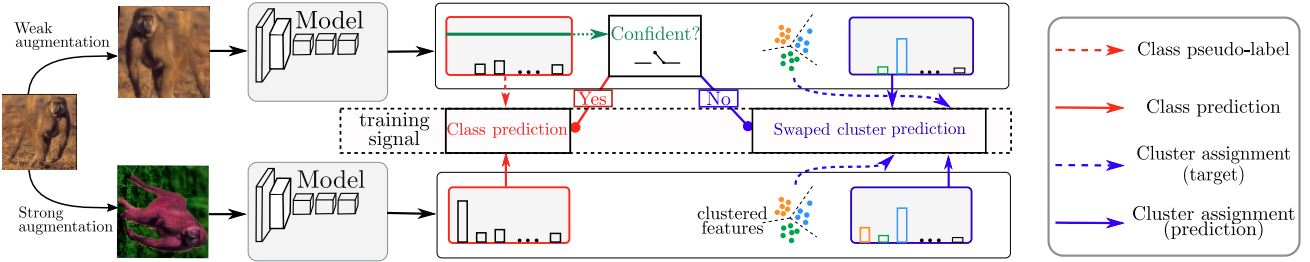
- representation learning (self-supervised learning, image retrieval, etc.)
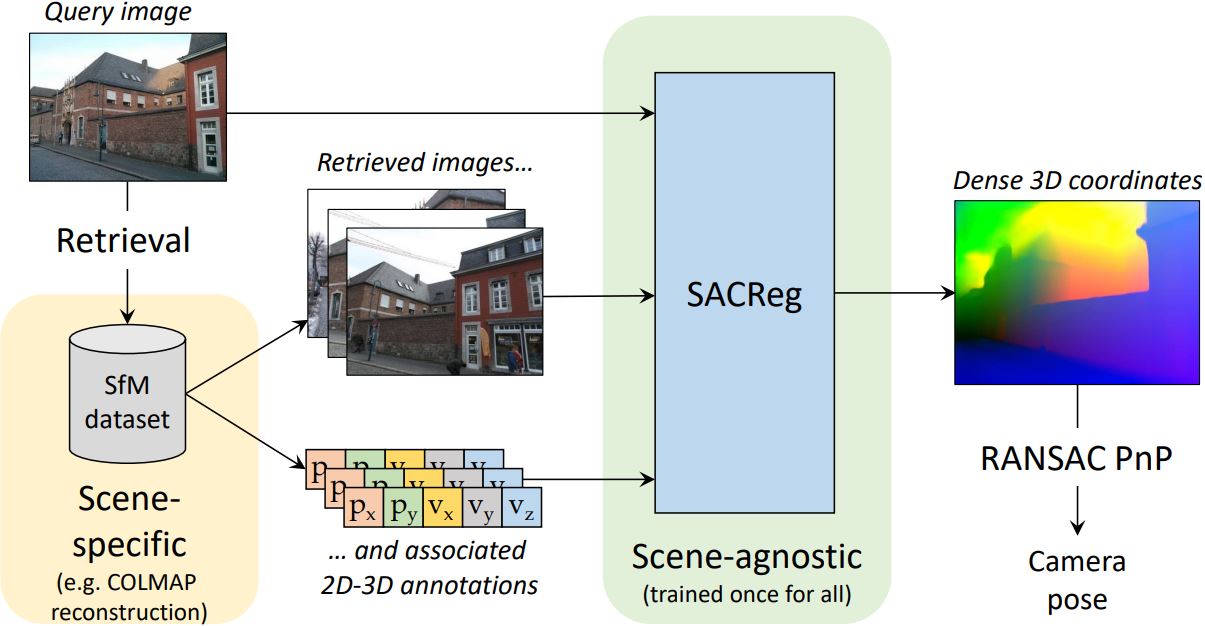
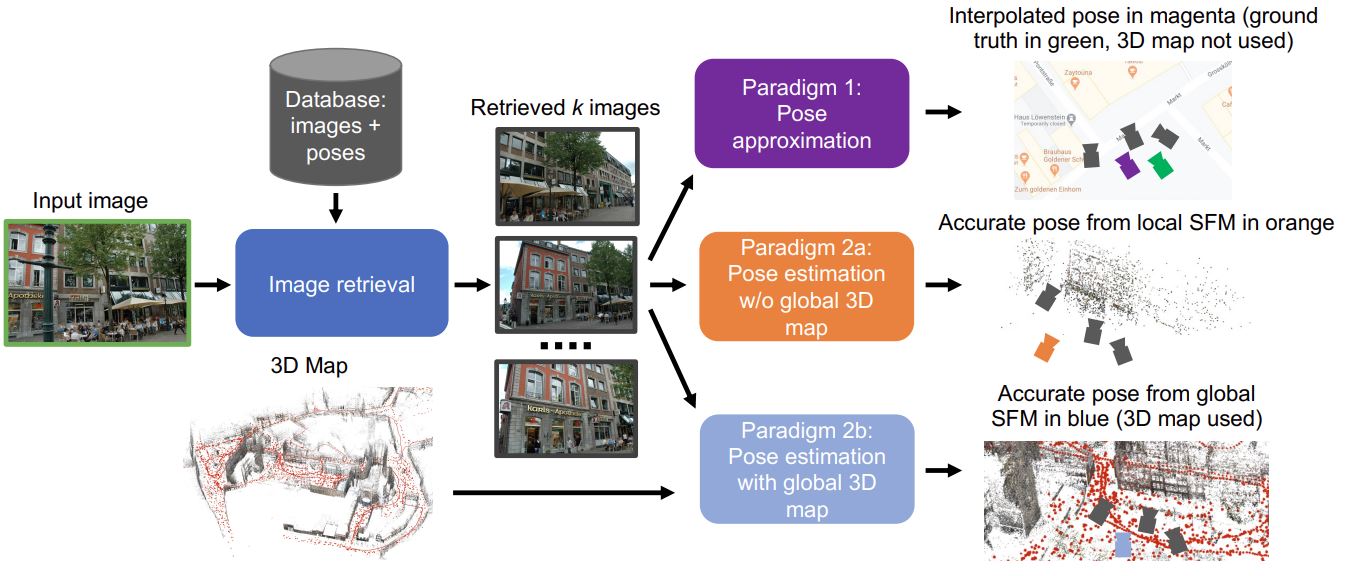
- geometric vision (image matching, 3D reconstruction, etc.)
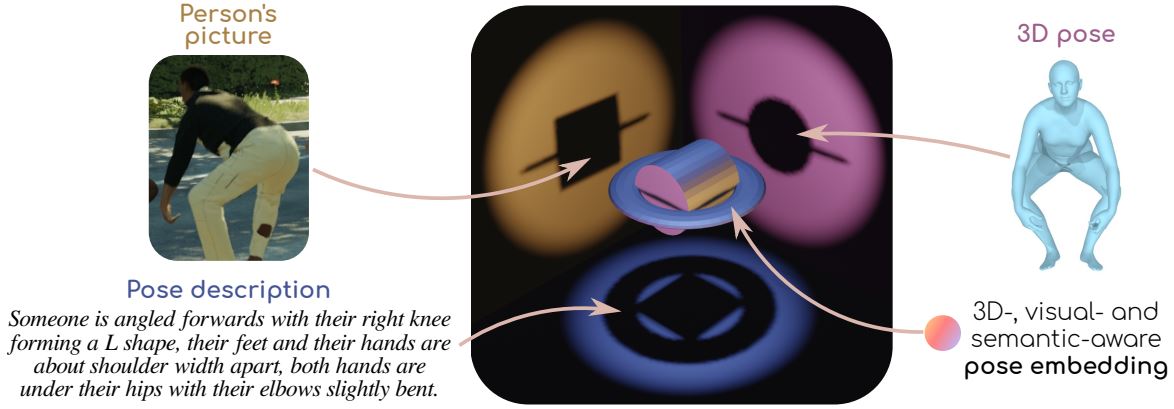
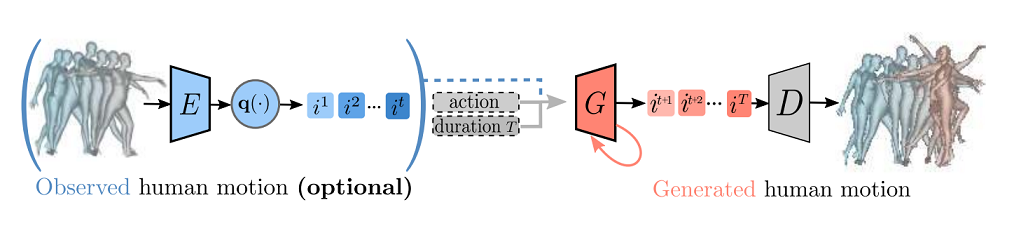
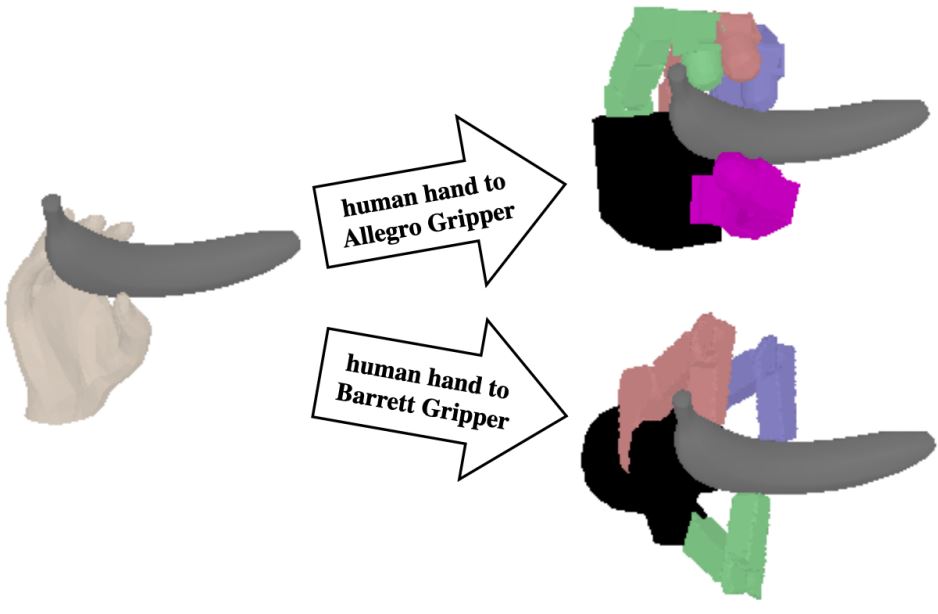
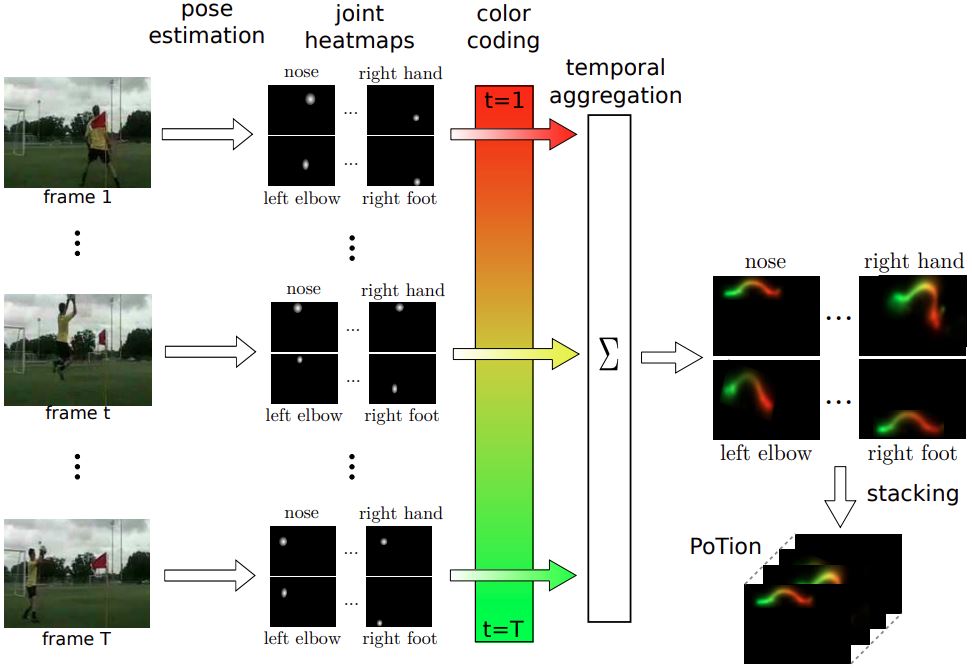
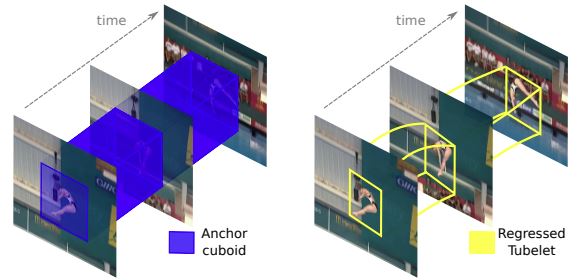
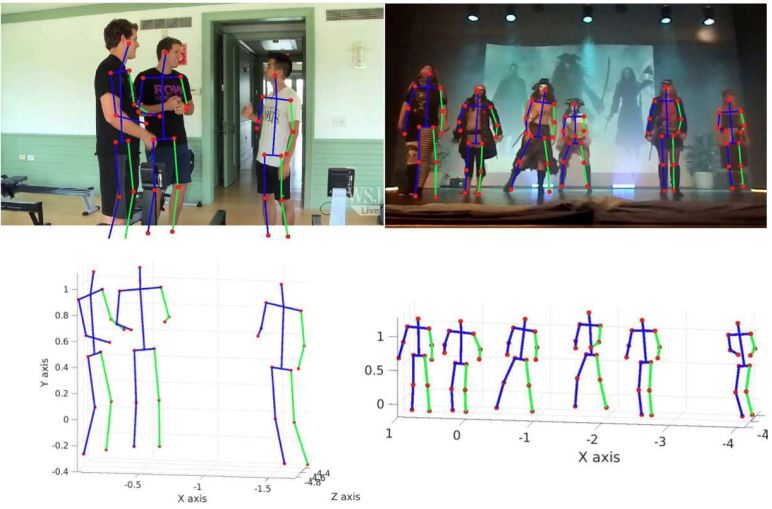
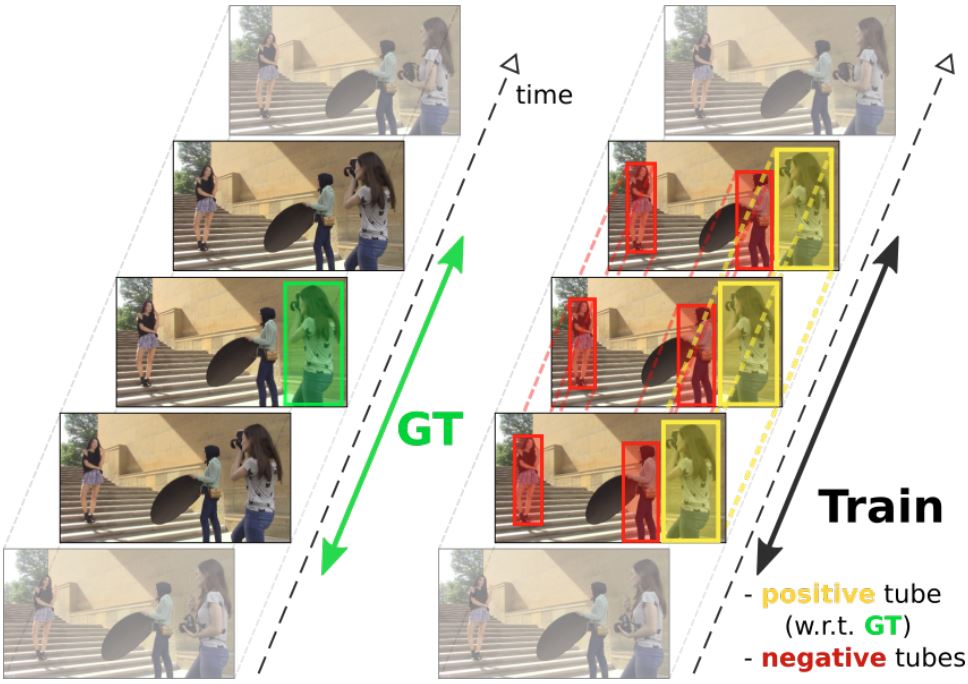
- human-centric vision (human pose estimation, action recongition, etc.)